How NOT to measure latency
last updated: Oct 20, 2023
Superb talk from Strange Loop 2015:
- The 95th percentile hides the really bad behavior of a system:
- The former graph, showing 95th percentile times, hides the latter graph, showing 99th:
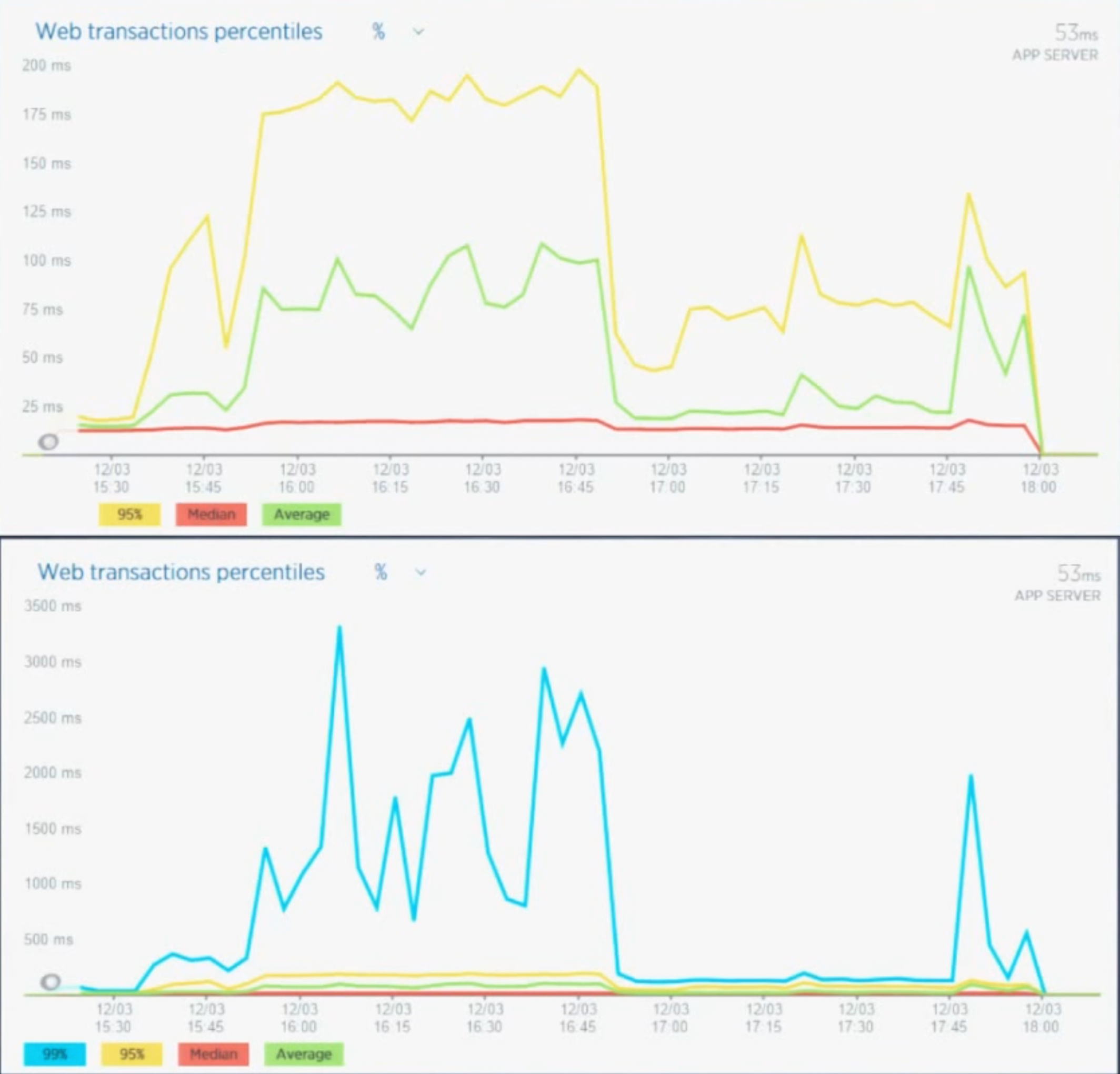
- Links this blog post breaking down a normal grafana chart
- Argues the maximum value is what you actually care about, not any percentile
- You cannot average percentiles
- (this drives me nuts, you see it all the time)
- Has a long segment about the likelihood of users seeing a given percentile in their response
- I think this part is a bit misguided
- assumes that there's an even likelihood of two users seeing slow responses
- implies that the effect of two users seeing slow responses on any request in a web session are directly comparable
- I think this part is a bit misguided
- Links to HDRHistogram, by the author, which is his attempt to solve the problem
- originally in java, with ports to several different languages
- github
- Coordinated omission
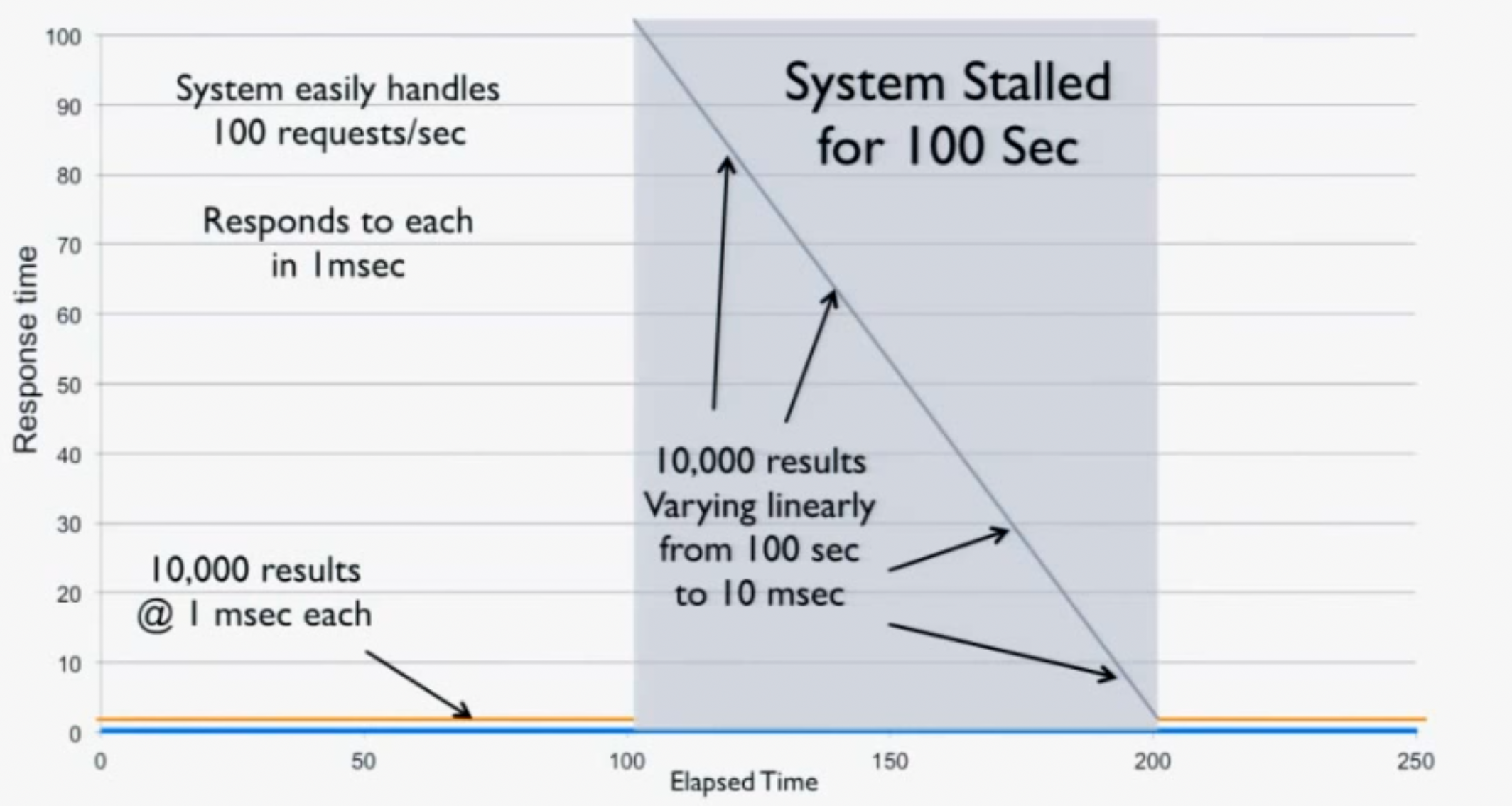
- in benchmarking, you must make requests at an even velocity, or you will fall victim to coordinated omission
- The basic idea is this: make 10 requests, but before request 5 stall the system for 10 seconds. The rest return in 1ms
- If you wait for each response to return, your response times look like:
[1,1,1,1,10001,1,1,1,1,1] - If you don't, you get:
[1,1,1,1,10001,10000,9999,9998,9997,9996]- which is an accurate measurement of the system
- This is an exaggerated example of an extremely persistent problem in measurement
- If you wait for each response to return, your response times look like:
- Be careful of measuring service time vs response time:
- service time is the time it takes to serve a request once it has arrived: t2-t1 on the web server
- response time is the time it takes for a request to get served, and includes time in the queue before being served
- Don't spend time optimizing/measuring how systems work after they've hit the wall
- what you care about is how they perform before they hit the wall, and making them more efficient so they serve more requests before hitting the wall
- he calls this "sustainable throughput"
- Gives a nice metaphor with a car crash: you want to improve your car so that it handles safely at higher speeds, rather than optimize the shape of the bumper so that it crashes better
- Compare systems by latency profiles at various loads:
