AI leaderboards are no longer useful
last updated: Apr 30, 2024
Our most striking result is that agent architectures for HumanEval do not outperform our simpler baselines despite costing more. In fact, agents differ drastically in terms of cost: for substantially similar accuracy, the cost can differ by almost two orders of magnitude! Yet, the cost of running these agents isn't a top-line metric reported in any of these papers.
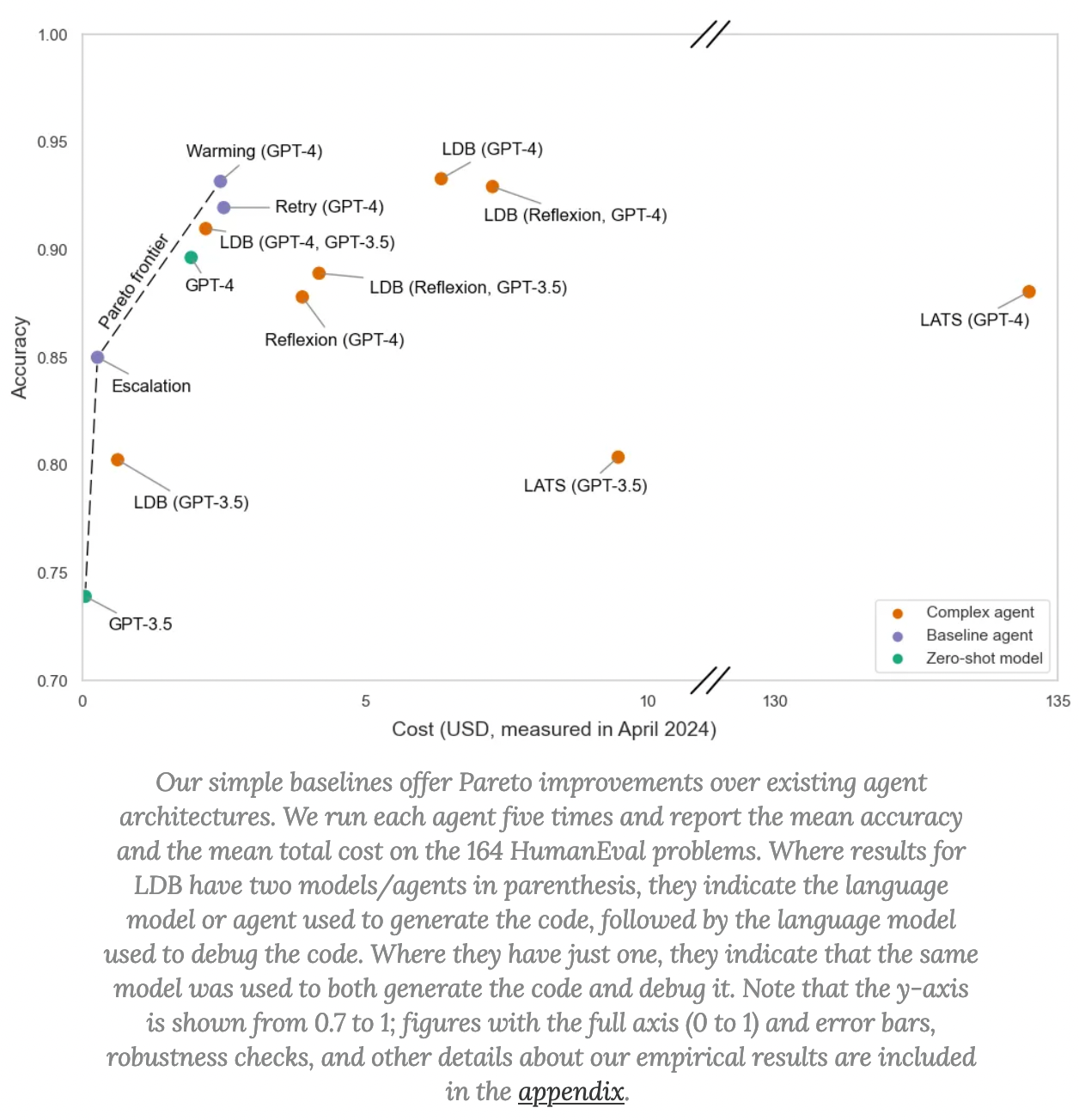
I like the ida that costs must be measured when benchmarking, and I think we should use that more widely than just in the AI sphere.
Wouldn't it be cool if we benchmarked python vs C++ on a problem, and included the cost to run the program? I'm not even sure how I would estimate it but it's fun to think about.